Seed-X-7B
综合介绍
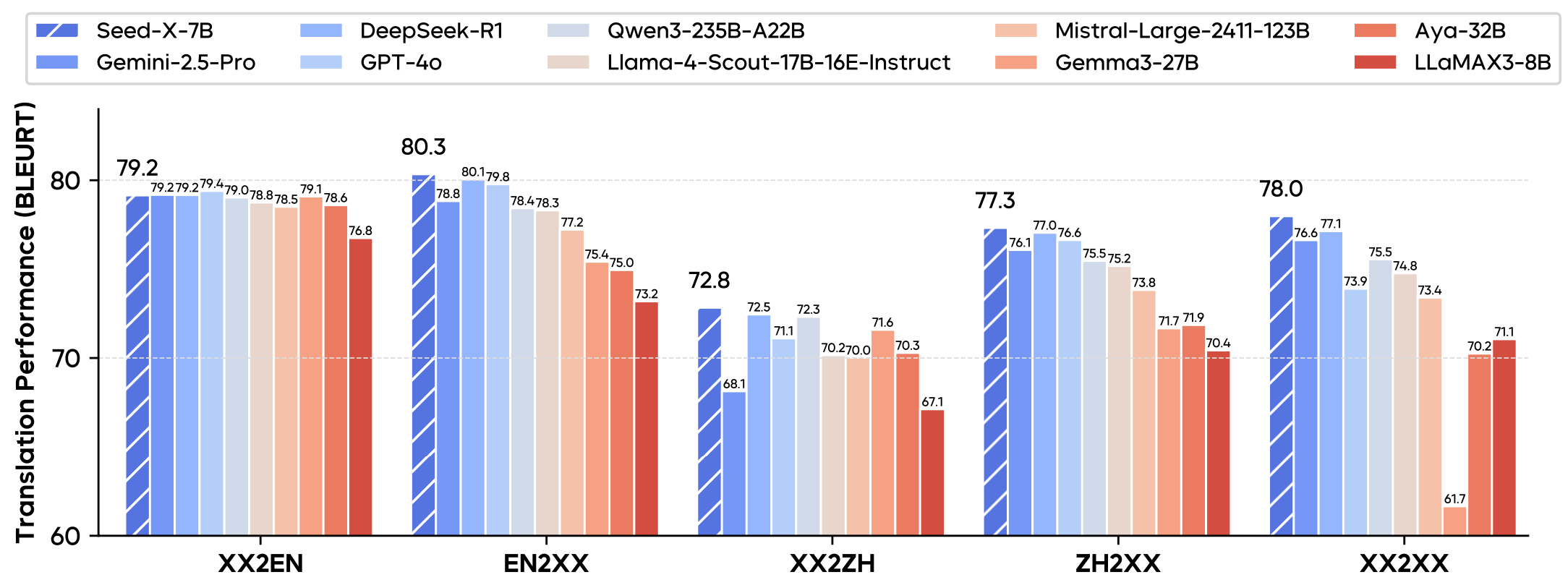
Seed-X是由字节跳动(ByteDance)的SEED团队开发并开源的一系列多语言翻译模型。 该系列模型参数规模为70亿(7B),专注于在28种不同语言之间提供高质量的双向翻译功能。 Seed-X基于Mistral架构进行设计,这种轻量化的设计使其在部署和推理时更加高效,适合在计算资源有限的环境中运行。 经过专门的翻译任务训练,其表现在多个领域(如科技、金融、法律和文学等)的测试中,可与Gemini-2.5、Claude-3.5和GPT-4等更大规模的闭源模型相媲美。 整个模型系列以宽松的MIT许可证开源,并在Hugging Face平台上提供,方便开发者和研究人员使用。
功能列表
- 高质量多语言翻译:支持阿拉伯语、中文、英语、法语、德语、日语、韩语和西班牙语等28种语言之间的高质量互译。
- 轻量化与高效率:采用70亿参数的Mistral架构,优化了部署和推理效率,适合资源受限的应用场景。
- 广泛的领域覆盖:在互联网、科技、办公对话、电子商务、生物医药、金融、法律、文学和娱乐等多个领域的翻译任务中表现出色。
- 多种模型版本:提供包括指令微调模型(Seed-X-Instruct)、强化学习模型(Seed-X-PPO)和奖励模型(Seed-X-RM)在内的多个版本,以满足不同应用需求。
- 开放源代码:项目代码和模型权重均在Hugging Face上发布,并采用MIT许可证,允许商业使用和二次开发。
使用帮助
Seed-X系列模型为开发者提供了开箱即用的多语言翻译能力。由于其开源特性和轻量化设计,开发者可以方便地在本地或云端环境中部署和使用。以下是详细的使用帮助,旨在让用户能够快速上手。
环境准备
开始使用Seed-X之前,你需要安装一些基础的Python库,主要是transformers和torch。
pip install torch
pip install transformers
选择合适的模型
Seed-X项目发布了多个模型,你需要根据自己的需求选择最合适的版本。官方推荐使用Seed-X-PPO模型,因为它在翻译性能上表现最佳。
Seed-X-PPO-7B:通过强化学习优化,翻译效果最好,是官方首推的模型。Seed-X-Instruct-7B:指令微调模型,作为基础的翻译模型使用。Seed-X-RM-7B:奖励模型,用于评估和判断翻译质量,适合研究场景。
快速上手:使用Transformers库加载模型
你可以通过Hugging Face的transformers库非常方便地加载并使用Seed-X模型。以下是一个使用Seed-X-PPO-7B模型进行中译英翻译的示例代码:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# 设定使用的设备,优先使用GPU
device = "cuda" if torch.cuda.is_available() else "cpu"
# 指定要加载的模型,推荐使用PPO版本
model_path = "ByteDance-Seed/Seed-X-PPO-7B"
# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16, # 使用bfloat16以获得更好性能
device_map=device
)
# 准备输入文本和Prompt
# Prompt格式为:Translate this from {源语言} to {目标语言}:\n{源语言文本}\nTarget:\n
source_lang = "Chinese"
target_lang = "English"
text = "你好,世界"
prompt = f"Translate this from {source_lang} to {target_lang}:\n{text}\nTarget:\n"
# 使用分词器对Prompt进行编码
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# 生成翻译结果
outputs = model.generate(**inputs, max_new_tokens=100)
# 解码输出结果并打印
# 注意:解码时跳过输入的token,只看生成的部分
translated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(translated_text)
操作流程和注意事项
- 无需聊天模板:Seed-X是一个专门用于翻译的模型,没有使用聊天模板(Chat Template)。因此,你不需要调用
tokenizer.apply_chat_template函数,直接按固定格式构造Prompt即可。 - Prompt格式:输入提示(Prompt)必须遵循固定的格式,即
Translate this from {源语言} to {目标语言}:\n{待翻译文本}\nTarget:\n。这里的{源语言}和{目标语言}需要用完整的语言名称替换,例如 "Chinese", "English"。 - 语言标签:在Prompt末尾提供源语言和目标语言的标签对于模型的翻译性能至关重要,因为模型在PPO训练阶段使用了这些标签。
- 模型量化:官方建议不要使用非官方的量化版本进行本地部署,因为这可能会影响模型的翻译质量和性能。
- 任务专一性:该模型专注于多语言翻译任务,在其他任务(如代码生成、数学推理或通用聊天)上的表现可能不佳。
支持的语言列表
模型支持28种语言的互译,以下是完整的语言列表及其简称。
| 语言 | 简称 | 语言 | 简称 | 语言 | 简称 | 语言 | 简称 |
|---|---|---|---|---|---|---|---|
| Arabic | ar | French | fr | Malay | ms | Russian | ru |
| Czech | cs | Croatian | hr | Norwegian Bokmal | nb | Swedish | sv |
| Danish | da | Hungarian | hu | Dutch | nl | Thai | th |
| German | de | Indonesian | id | Norwegian | no | Turkish | tr |
| English | en | Italian | it | Polish | pl | Ukrainian | uk |
| Spanish | es | Japanese | ja | Portuguese | pt | Vietnamese | vi |
| Finnish | fi | Korean | ko | Romanian | ro | Chinese | zh |
应用场景
- 内容本地化企业网站、应用程序或技术文档需要面向全球用户时,可以使用Seed-X将内容快速翻译成多种目标语言,提升产品的国际化水平。
- 跨语言交流在在线聊天、电子邮件或社交媒体等场景中,集成Seed-X可以实现实时的跨语言沟通,帮助不同语言背景的用户无障碍交流。
- 学术研究辅助研究人员可以利用Seed-X翻译国外的学术论文、期刊和文献,以快速获取前沿的科研信息。其在多个专业领域的翻译能力保证了结果的准确性。
- 多语言媒体内容制作对于视频创作者或媒体公司,Seed-X可以用于快速生成视频字幕、新闻稿和宣传材料的多语言版本,扩大内容的影响力。
QA
- Seed-X模型和其他大型模型(如GPT-4)相比有什么优势?Seed-X的主要优势在于其轻量化和专业化。它以仅70亿的参数规模,在多语言翻译任务上实现了与GPT-4等超大模型相当的性能。 这意味着它对计算资源的需求更低,部署成本更优,更适合需要高效翻译功能的特定应用场景。
- 我应该选择哪个Seed-X模型进行部署?官方推荐使用
Seed-X-PPO-7B模型,因为它经过了强化学习的额外优化,翻译表现是所有版本中最好的。 如果你有评估翻译质量的特殊需求,也可以研究Seed-X-RM-7B奖励模型。 - 使用Seed-X时,为什么必须遵循特定的Prompt格式?Seed-X在训练时,特别是通过强化学习微调时,依赖于特定的指令格式来理解任务。
Translate this from {源语言} to {目标语言}:这样的结构能让模型准确识别翻译的方向,从而生成更高质量的翻译结果。 - 这个模型可以用于聊天或者写代码吗?不可以。Seed-X在训练过程中特意排除了与代码、数学和通用推理相关的数据,专注于提升翻译的准确性和效率。 因此,它不适合用于通用聊天、编程辅助或其他非翻译任务。